
Pragmatic CS #2: ML Engineering
Bayesian Optimization of quantization bit widths, reuse data for training during upstream bottlenecks, Facebook's optimisation of a real-time text-to-speech system and

Hello friends,
This edition of Pragmatic CS brings you 3 exciting recent developments in practical ML Engineering! Much is written out there about how to implement the latest state-of-the-art models. We don’t need another article on using YOLO v4 to do real-time object detection, or creating RoBERTa embeddings for sentences.
Not enough is said about the engineering needed to make these models work well in production. That is the focus of today’s newsletter. One of my favourite writers on this topic is Eugene Yan. He is an Applied Scientist at Amazon, and former VP of Data Science at Lazada (Southeast Asia's largest e-commerce platform, acquired by Alibaba).
Faster Neural Network Training With Data Echoing

Upstream operations (eg. Disk I/O and data preprocessing) in the neural network training pipeline do not run on hardware accelerators.
“Data echoing” reuses intermediate outputs from earlier pipeline stages when the training pipeline has an upstream bottleneck. This maximises hardware utilisation. The number of times data is reused is set as the echoing factor. The effectiveness of this approach challenges the idea that use of repeated data for SGD updates is useless or even harmful.
Echoing can be done:
Before batching – data is repeated and shuffled at the training example level, increasing the likelihood that nearby batches will be different. This has the risk of duplicating examples within a batch.
After batching
Before augmentation – allows repeated data to be transformed differently, potentially making repeated data more akin to fresh data
After augmentation – other methods like dropout that add noise during the SGD update can make repeated data appear different
Data echoing reduces the number of fresh examples required for training and the training time, without harming predictive performance (up to a upper bound on the echoing factor). There is also empirical evidence of data echoing performing better with larger batch sizes and more shuffling.
Bayesian Optimization of Quantization Bit Widths Together With Pruning
Managing complexity before deployment of a neural network for inference involves 2 techniques:
Quantization – reduction of the bit width of weight and activation tensors.
Model compression – reducing the number of network parameters. Reduces the total number of multiply-accumulate (MAC) operations required.
Instead of fixing a bit width for all tensors or doing an exhaustive search, this paper learns appropriate bit widths for each tensor in an end-to-end manner through gradient descent.
Sequentially considers doubling the bit width (power of 2 always produces hardware-friendly configurations)
At each new bit width, the residual error between the full precision value and the previously rounded value is quantized
Decide whether or not to add this quantized residual error for a higher effective bit width and lower quantization noise
You can unify this quantization method with pruning by adding the option of a 0-bit. The weight and activation tensors assigned a 0-bit are effectively pruned.
Add learnable stochastic gates to collectively control the bit width of the given tensor. Performing approximate inference over the gates, with prior distributions that encourage most of them to be switched off, results in low-bit solutions that provide a better tradeoff between accuracy and efficiency than static bit widths.
How Facebook Optimised a Real-time Text-to-Speech System for Deployment on CPUs
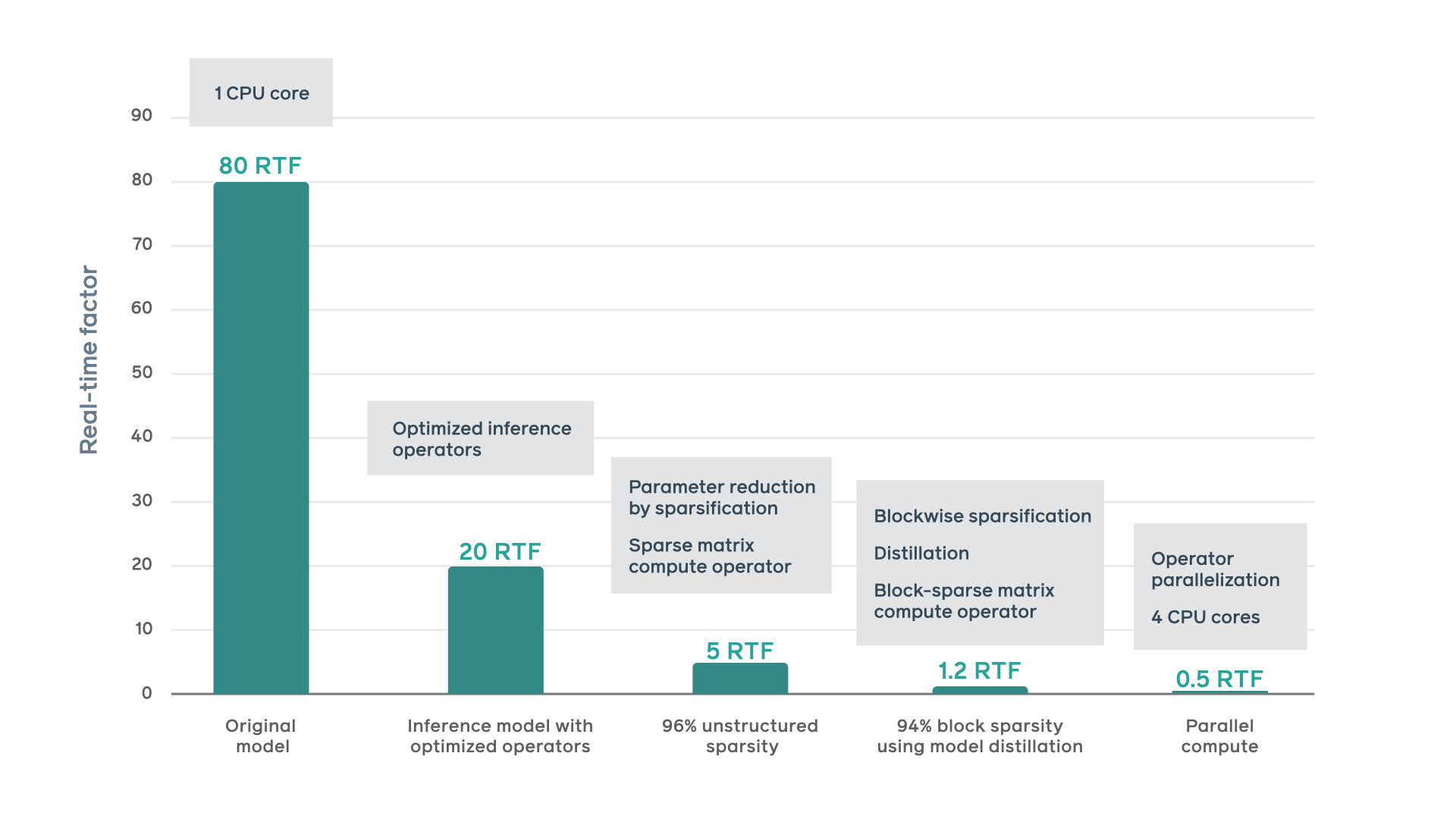
Facebook increased synthesizing speed by 160x, using model system co-optimization techniques:
Tensor-level optimizations and custom operators
Adopted efficient approximations for the activation functions
Operator fusion to reduce the total operator loading overhead
Unstructured model sparsification
Blockwise sparsification
Nonzero parameters are restricted in blocks of 16x1 and stored in contiguous memory blocks
Trained the sparse model through model distillation, using the dense model as a teacher model
Distributed heavy operators over multiple cores on the same socket
During training: enforced that nonzero blocks be evenly distributed over the parameter matrix
During inference: Segmented and distributed matrix multiplication among several CPU cores
Have ideas to discuss? Feel free to reply directly, or leave a comment.
Forward this to a friend who might find it helpful!